Posts by Joseph Stateson
|
21)
Message boards :
Questions and problems :
Boinc.exe terminates at start on W10
(Message 110444)
Posted 14 Nov 2022 by  Joseph Stateson Joseph Stateson
Post: Having problem running BOINC, since it terminates when it starts. Possibly two problems BOINC, or what remains of BOINC, may reside in memory from the last time it was run due to a crash. BOINC may have established a connection to port 31416 and that connection was not properly closed. You can run the command netstat from an administrator prompt to determine if a port is open or closed. For example C:\Windows\system32>netstat -aon | find "31416" TCP 0.0.0.0:31416 0.0.0.0:0 LISTENING 1236 TCP 127.0.0.1:31416 127.0.0.1:49870 ESTABLISHED 1236 TCP 127.0.0.1:49870 127.0.0.1:31416 ESTABLISHED 7420 TCP 127.0.0.1:55649 127.0.0.1:31416 TIME_WAIT 0 TCP 127.0.0.1:55663 127.0.0.1:31416 TIME_WAIT 0 TCP 192.168.1.184:31416 192.168.1.241:50430 ESTABLISHED 1236
|
|
22)
Message boards :
GPUs :
Bad or incompatible GPU?
(Message 110423)
Posted 12 Nov 2022 by Joseph Stateson
Post: finally got a handle on the problem. i booted windows 10 and the system worked fine Problem was the 22H2 update to windows 11 Googling "22H2 slowdown" brought up a motherload of complaints I put the win11 drive back in and I and tried every suggestion that google dished up but was stuck at under %50 utilization no matter what option I enabled or disabled. It has been 10 days since 22H2 went in so no easy way to get back to when the system was working. All windows 11 recovery points are after 22H2. Going to beg on answers.microsoft.com. This system is old but was qualified for windows 11 |
|
23)
Message boards :
GPUs :
Bad or incompatible GPU?
(Message 110406)
Posted 10 Nov 2022 by Joseph Stateson
Post: Problem is the CPU / Motherboard or recent BIOS upgrade / Windows 11 feature update that all happened over a 2 day period The problem was not the GPU. |
|
24)
Message boards :
GPUs :
Bad or incompatible GPU?
(Message 110389)
Posted 9 Nov 2022 by Joseph Stateson
Post: Think I have a bad or incompatible RTX-3070. RTX-2080 went dead in a Win11 gen3 express system (Area51) and Gigabyte replaced it under warranty with RTX-3070. They did not have any more 2080 I observed the following problem briefly discussed over at Boinctasks All my CPU tasks are running at less than %50 utilization. The top 6 Universe were run on an i9-7900x at 3.3ghz The bottom Universe on an old Xeon x5650 at 2.67ghz and complete 2x as fast as the i9 cpu. All CPUs were allowed %100. There is no thermal throttling. The previous system with RTX2080 the CPU was always %100 busy Either the graphics board is defective or the gen4 express is causing problems in a gen3 system. The GPU tasks runs fine, just a problem with the CPU utilization. 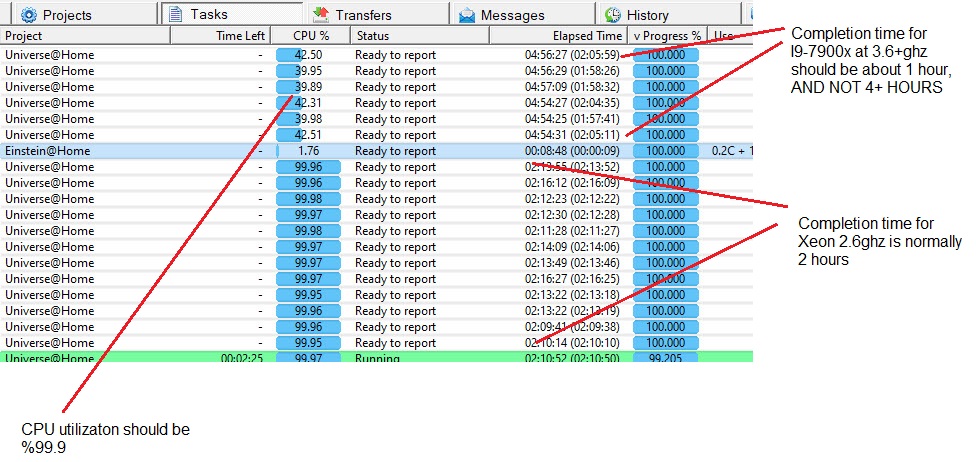 [/img] [/img]
|
|
25)
Message boards :
Projects :
Cosmology's certificate has expired again
(Message 110385)
Posted 9 Nov 2022 by Joseph Stateson
Post: http works find but not https https://www.cosmologyathome.org/ Existing system with that project work fine but I cannot log into my account or view results as https is required I have read where this has happened several times over the years.. |
|
26)
Message boards :
Questions and problems :
Install of client failed to obtain the service script
(Message 110368)
Posted 8 Nov 2022 by Joseph Stateson
Post: OK, found problem (there was none) Some ubuntu release puts the script into /usr/lib/systemd/system others use /lib/systemd/system when the app did not run, I looked at /lib and it was not there and I assumed that was the problem. |
|
27)
Message boards :
Questions and problems :
Install of client failed to obtain the service script
(Message 110359)
Posted 7 Nov 2022 by Joseph Stateson
Post: sudo add-apt-repository ppa:costamagnagianfranco/boinc followed by install of boinc-client failed to install the service script at /lib/systemd/system This occurred after a clean install of 18.04.6 The scriipt was installed just fine when I tried 22.04.1 I assume I can no longer use 18 and will have to find out why my RX570 drivers failed to install in 22.04 Is there any reason why the service script did not get installed using the franco repository? |
|
28)
Message boards :
Questions and problems :
Illegal opcode on new install of 22.04
(Message 110357)
Posted 7 Nov 2022 by Joseph Stateson
Post: Too late to edit my post. I assume the problem of the illegal opcode is related to the android version being placed into the distribution as discussed over at Github No longer using 22.04 as I had problems with AMD drivers for OpenCl in addition to BOINC permission problems. However, the boinc versoin from sudo add-apt-repository ppa:costamagnagianfranco/boinc worked fine |
|
29)
Message boards :
Questions and problems :
Illegal opcode on new install of 22.04
(Message 110346)
Posted 6 Nov 2022 by Joseph Stateson
Post: Consistent every time I run the start script or even ask for version kern.log:Nov 6 17:05:59 dual-linux kernel: [ 1840.265297] traps: boinc[3522] trap invalid opcode ip:55de226c06a8 sp:7ffe42695620 error:0 in boinc[55de226b6000+c3000]
|
|
30)
Message boards :
Questions and problems :
Duplicate CPID
(Message 106583)
Posted 28 Dec 2021 by Joseph Stateson
Post: For the machine you need to change the CPID to the correct one, just edit its client_state.xml file and change the CPID in the <external_cpid>{CPID}</external_cpid> field and save the file. I just went through this as un-accountably, einstein had not put a value in the extern_cpid field The value in there is the one for all your systems, the one that starts with 53... https://www.gridcoinstats.eu/cpid/53ed9d9b7d568cb7eb1ccc25a7dc4492 Hopefully you do not have different external CPIDs which is a PITA to fix. [edit] I do not see any of your system addresses. Either you have another account or the systems have not propagated their CPID into the eu stats table. if you put in my name you will see 5 active addresses each corresponding to a system CPID and under that the four main projects I work on. You should have a single external CPID good for all your work. |
|
31)
Message boards :
Questions and problems :
Boinc Manager Keep Stop Workinig
(Message 106550)
Posted 27 Dec 2021 by Joseph Stateson
Post: Look in the windows event viewer at both Applications and System for warnings or errors. Often the logs are so large it is hard to find things. I would delete the logs, reboot then try to add a project then go back to the the event log and look for error messages near the time you attempted to add a project. I suspect some type of system problem. |
|
32)
Message boards :
Questions and problems :
Windows 11 ssh and remote desktop still not work with GPU?
(Message 106546)
Posted 27 Dec 2021 by Joseph Stateson
Post:
Do not use the pro version, sorry. I did pay for the Splashtop remote subscription so I can use my cell phone to access my systems but I am using the "5 free one" version even on Splashtop. |
|
33)
Message boards :
Questions and problems :
Getting too may WCG tasks on systems that had been working ok
(Message 106541)
Posted 26 Dec 2021 by Joseph Stateson
Post: Follow-up on this problem. All my WCG systems have stabilized after a week of 24/7 and I got a "solution" to setting Priority to 0 with that max_concurrent app option. Recap: Setting Priority to 0 normally means the queue never exceeds 1 work unit even if each core is working on a WCG task. During initial configuration of BOINC it is possible a lot of unwanted work units will download but eventually the system will get to where a new download occurs only when there are not other tasks of the same type (CPU) in the queue. This is a different problem. When using "max_concurrent" in WCG's app_config file, I was able to demonstrate that Priority of "0" is ignored if the number of cores allocated to the system is greater than the value of that max_concurrent parameter. On my test system, I left # cores at 11 with max_concurrent at 8 and the number of WCG tasks increased to several 100. However, at no time did the number of waiting work units exceed the deadline. As long as I left the system running 24/7 they would all finish in within the dead line. When I set the number of cores down to 8, the same value as max_concurrent, there were no more downloads of work units and eventually the queue got down to 0 at which time a single download occurred. This is the expected behavior for Priority of 0. Probably not many users have priority set to 0. Should this problem should be reported as an issue over at github? Can someone else verify this behavior? Thanks for looking! |
|
34)
Message boards :
Questions and problems :
Inconsistency in "Project List"
(Message 106456)
Posted 18 Dec 2021 by Joseph Stateson
Post: BM is independent of BOINC so you need to address this question with them, bearing in mind than some projects do not share all their information with third parties of any one of a great number of reasons/excuses. I am confused. I thought the Boinc Manager (BM) was part of the Boinc project since there is only one github "boinc" project. [EDIT] You are probably thinking of "BAM!" a 3rd party. I mean the Boinc Manager that comes with Berkeley's boinc download. |
|
35)
Message boards :
Questions and problems :
Inconsistency in "Project List"
(Message 106454)
Posted 18 Dec 2021 by Joseph Stateson
Post: I am working on a pet project where I analyze the job_log files. Some are old retired projects, others active. The job log is named in a way that partially identifies the actual project and I wanted to look up the info and get the "real name" of the project. BM uses "get_all_project_list" an RPC call that I do not want to replicate plus it does not get everything. In the boinc folder there is a file "all_projects_list.xml" but is is missing, for example, Asteroids@home. I only noticed that because it starts with "A" and was one of the first I looked for. It shows up in the manager when "add project" is selected so I am not sure why it is missing from that all_projects_list file. If BM creates that "all_project_list.xml" why is it missing that Asteroids project? |
|
36)
Message boards :
Questions and problems :
Inconsistency in project url for WCG
(Message 106453)
Posted 18 Dec 2021 by Joseph Stateson
Post: When using BM to add World Community Grid the prefix https is used Unaccountably, WCG complains that it need to be "http" and I get 1000's of error messages that show up like this: lenovos20 56 World Community Grid 12/17/2021 2:02:52 PM This project seems to have changed its URL. When convenient, remove the project, then add http://www.worldcommunitygrid.org/ That message originates in the client and is not from the project. It is generated when the reply url is not the same as the current url. I scanned some of the xml in ProgramData\boinc in my lenovo system and found the following --------- SCHED_REPLY_WWW.WORLDCOMMUNITYGRID.ORG.XML
<master_url>http://www.worldcommunitygrid.org/</master_url>
<url>https://www.worldcommunitygrid.org/research/viewAllProjects.do</url>
---------- SCHED_REQUEST_WWW.WORLDCOMMUNITYGRID.ORG.XML
<source_project>https://www.worldcommunitygrid.org/</source_project>
C:\ProgramData\BOINC>find /i "http:" *world*.xml
---------- ACCOUNT_WWW.WORLDCOMMUNITYGRID.ORG.XML
---------- MASTER_WWW.WORLDCOMMUNITYGRID.ORG.XML
---------- SCHED_REPLY_WWW.WORLDCOMMUNITYGRID.ORG.XML
<master_url>http://www.worldcommunitygrid.org/</master_url>
---------- SCHED_REQUEST_WWW.WORLDCOMMUNITYGRID.ORG.XML
---------- STATISTICS_WWW.WORLDCOMMUNITYGRID.ORG.XMLOn the systems where I did the detach and re-attach the following differences D:\ProgramData\Boinc>find /i "http:" *world*.xml
---------- ACCOUNT_WWW.WORLDCOMMUNITYGRID.ORG.XML
<master_url>http://www.worldcommunitygrid.org/</master_url>
---------- MASTER_WWW.WORLDCOMMUNITYGRID.ORG.XML
---------- SCHED_REPLY_WWW.WORLDCOMMUNITYGRID.ORG.XML
<master_url>http://www.worldcommunitygrid.org/</master_url>
---------- SCHED_REQUEST_WWW.WORLDCOMMUNITYGRID.ORG.XML
<source_project>http://www.worldcommunitygrid.org/</source_project>
<source_project>http://www.worldcommunitygrid.org/</source_project>
---------- STATISTICS_WWW.WORLDCOMMUNITYGRID.ORG.XML
<master_url>http://www.worldcommunitygrid.org/</master_url>So, after detaching and re-attaching all the request, reply, sched xml files are consistent as "http". I have had to do this on every system as that error message is printed up for every transaction which make the log file badly cluttered. What is strange is that the client_state.xml uses https and does not generate any problems and for that matter, not making the HTTP change has only a cosmetic effect: Lot of error message. I assume the fix to this is to have WCG use "https" in their reply. Alternately, it would be nice if once the user is notified there are no further error messages from the same project. For that matter there should be no back-to-back identical error messages. Observation: If WCG got the "request" and "replied" then why is there a problem? If they cannot reply because the url is wrong there is obviously a real problem. |
|
37)
Message boards :
Questions and problems :
missing project in BM project list
(Message 106452)
Posted 18 Dec 2021 by Joseph Stateson
Post: The project "WUProp@home" is missing from BM's "add project" It is listed here https://boinc.berkeley.edu/wiki/Project_list How does one go about getting a project added so it shows up when the manager does an RPC "get_all_project_list" call? There is a contact number at this location for adding https://boinc.berkeley.edu/projects.php but I suspect that does not get onto the BM RPC call database and someone at the project needs to make the request in any event. |
|
38)
Message boards :
Questions and problems :
Getting too may WCG tasks on systems that had been working ok
(Message 106446)
Posted 16 Dec 2021 by Joseph Stateson
Post:
I think the only exception to large download limit is that "lost task" download but my tasks were not lost, they were aborted due to no possibility of finishing. An observation that might be be a clue: One of my win10 + NVidia systems has app_config with max concurrent of 9 but does not and never had a problem with too many WCG downloads. However, I set max number of core to 9 on that system and it also runs one Einstein. I am guessing the max_concurrent is not used as the # of cores limit takes precedence in the fetch algorithm??? My linux system uses max cores to limit wcg and not app_config and it does not and never had a problem. |
|
39)
Message boards :
Questions and problems :
Getting too may WCG tasks on systems that had been working ok
(Message 106445)
Posted 16 Dec 2021 by Joseph Stateson
Post: Just checked my Lenovo again. More tasks have downloaded but the deadline has not changed. There are 135 tasks waiting. At 4 hours per task and 8 cores that is 68 hours of work and is still within the deadline of 12/23. However, there should have been no downloads with project priority of 0. Perhaps that feature (the "0") is not a "client" specification anymore if it ever was. I have been using it as a fallback project so if Milkyway runs dry (like just happened recently) then Einstein gets to run but as soon as one Einstein finishes Milkyway can take over since it is 100% and Einstein is %0. AFAICT WCG is the only project where the "0" has a problem. I do not want to babysit WCG. if it wants to download 1700 apps I do not want to crunch apps that will not be used. I have spotted 100's of their apps as "aborted by project" on my system and have been trying to figure out how to prevent it. Project priority of "0" does not work on some system and on others it does. As I have been writing this post that WCG app count went from 135 to 145. If I shut the system down for a long weekend about 1/2 will be expired before they even start. |
|
40)
Message boards :
Questions and problems :
Getting too may WCG tasks on systems that had been working ok
(Message 106443)
Posted 16 Dec 2021 by Joseph Stateson
Post: After installing that "max fix" version on 3 system I got one system that responded after "allow new work" On the LenovoS20 that had 8 apps running (max concurrent is 8) and with no apps waiting there were two back to back downloads that totaled 14 days / 84 work units. That actually can be done as calculating 4 hours per core and 8 cores with deadline of 12/22 through 12/23. All 84 apps should finish in about 42 hours. The problem is that NONE should have downloaded with share of 0. The other two systems I put the "max fix" on had a day of WCG already waiting so I assume that affected the "allow new work" differently and they were not tempted into downloadiing more stuff. The net effect is that (1) I am confident my 7.16.3 "special" that contains a coding "mod" for the Milkyway idle problem did not cause the WCG problem. I do plan to update that app eventually. (2) there is a problem with WCG and/or the client config as some of my systems work perfectly with share=0 on WCG and others do not. I suspect most users do not use share=0 so no complaints. |
Previous 20 · Next 20
Copyright © 2024 University of California.
Permission is granted to copy, distribute and/or modify this document
under the terms of the GNU Free Documentation License,
Version 1.2 or any later version published by the Free Software Foundation.