7.14.2 and 7.12.1 both fail to get work units on very fast systems
Message boards :
BOINC client :
7.14.2 and 7.12.1 both fail to get work units on very fast systems
Message board moderation
Previous · 1 · 2
| Author | Message |
|---|---|
|
Send message Joined: 5 Oct 06 Posts: 5103 
|
When I look at https://milkyway.cs.rpi.edu/milkyway/server_status.php it says at the bottom Task data as of 29 Apr 2019, 10:41:21 UTC. That's about 20 minutes ago. A LOT can change in 20 minutes, so it now showing to have 11683 tasks RTS means that they were that number at 10:41:21 UTC, not now. Aside from that, even if that number is a constant 11K+, you still don't know how many tasks were in the feeder at the given moment your client asked for work. If there were none, or way fewer than you're asking for, it won't give you work.Also, two other things are not included in their (BOINC standard) template SSP: Number of tasks available per app - NBody or separation. It wouldn't help if most of the 11683 were NBody. Number of tasks reported per hour - with a maximum runtime of 43 seconds, that could be huge. (22377 recent computers all doing a task every 40 seconds is over 2 million tasks reported every hour - you get an idea how much is actually happening under the hood) ID: 91255 · |
 Joseph Stateson Joseph StatesonSend message Joined: 27 Jun 08 Posts: 641 
|
With not much to do since I retired, I am having fun looking at this problem. I discovered the rpcClient library (thanks a lot!) and wrote a program to check the number of tasks remaining using a 2 minute timer and then automatically issue an update to my system on the next 2 minute tick. That guarantees (assuming not off-line) about a 4-6 minute maximum empty gap. Sure enough it worked about 2am, 6 hours ago exactly. Picture of "count down" is HERE Graph of last 8 hours is HERE I didn't restart the program so there were two additional gaps of 13 minutes that occurred in the hours afterwards. ID: 91256 · |
|
Keith Myers Send message Joined: 17 Nov 16 Posts: 879
|
Hope this information gets passed on to Eric or Tom. Since Jake is leaving the project shortly he won't be our project contact anymore. ID: 91258 · |
|
Joseph Stateson Send message Joined: 27 Jun 08 Posts: 641
|
Hope this information gets passed on to Eric or Tom. Since Jake is leaving the project shortly he won't be our project contact anymore. This whole thing is just storm in a teacup. One should be contributing to other projects that are just as deserving whether a deficiency in scheduling or not. All my programs are at GitHub\BeemerBiker and can be built with VS2017. Hope someone finds them useful. I had a lot of fun writing them, especially the Spider Solitaire solver. ID: 91259 · |
|
Keith Myers Send message Joined: 17 Nov 16 Posts: 879
|
But if there is a deficiency in the server or client code, the issue should be passed on to the developers at https://github.com/BOINC/boinc Likely as Richard pointed out, the feeder is probably not set correctly for how many tasks are requested by so many fast hosts. ID: 91260 · |
|
Send message Joined: 4 Jul 12 Posts: 321 
|
This really looks like a server issue to me. When I had this kind of problem on Einstein@home what usually helped was looking at the scheduler logfile of the server which can be made more verbose and print out reasons why certain work was or was not chosen for a host. What I didn't read in this thread is if the limits (per GPU, per CPU and total) are reached or not. That would be my first guess that can be easily checked on the server. The other thing that may cause this is that the demand for each MW application is different and so the space in the shared memory array that the feeder accesses needs to be divided according to demand. This is done by setting the priority for each application by the project administrator. After restarting the feeder and scheduler (if run as FCGI) there might be more room for the application in high demand. Another metric that the administrator should look at is the number of tasks added to the shared memory array with each feeder run (every 5 sec). If you fill up the whole array each time you need to make it bigger or your tasks longer. If the array is not drained quickly but users complain about "0 tasks sent" than there must be something else wrong in how the scheduler finds work for a host with a work request (back to looking at the scheduler log and requests from hosts that show this problem). ID: 91262 · |
|
Send message Joined: 4 Jul 12 Posts: 321
|
As a sidenote: there are some more interesting metrics that paint a better picture of the "throughput" of a project that are not shown on the SSP. One of them is the number of validated workunits per day which can be gathered from the validator logfile by counting specific lines using a grep command. The number of "satisfied" and "unsatisfied" work requests is also nice to have but not so easy to gather as this is in the scheduler log and not easily correlated (at least EaH hasn't found an easy way). ID: 91264 · |
|
Send message Joined: 29 Apr 19 Posts: 19 
|
Read it. But am still sure that problem is not with the supply of the work.When I look at Why feeder should not give work if client asks more than it have it moment? It should give less (up to max it has) but not zero. Oh, wait - it is actually already works this way on all projects i have tried - if client ask too much work - server just send "some" work, not refuse to give work at all. And give some more at next request after delay expire and so on - until client thinks it has enough or hit server daily quota. ID: 91343 · |
|
Send message Joined: 29 Apr 19 Posts: 19
|
Well if you check my log you will see that my computers not so fast and finish MW tasks only in about 3 minutes (actually 11-13 min to finish task but it runs 4 tasks in parallel, so one task finished every 3 mins or so). It more compared to 91 sec server issued delay. Plus there is a some variation in timings it 2-5 min between requests, not constant exact 3 min delay . So "synchronization" between client should not be the case - as there is enough randomness without manual updates. And no - why you think that 'zero sent' continues even after the cache is empty? Log shows the opposite (https://pastebin.com/8LCxm5RN): 29/04/2019 05:07:31 | Milkyway@Home | Computation for task de_modfit_80_bundle4_4s_south4s_0_1555431910_4469895_0 finished 29/04/2019 05:08:16 | Milkyway@Home | Computation for task de_modfit_84_bundle4_4s_south4s_0_1555431910_4347759_1 finished 29/04/2019 05:08:30 | Milkyway@Home | Sending scheduler request: To fetch work. 29/04/2019 05:08:30 | Milkyway@Home | Reporting 2 completed tasks 29/04/2019 05:08:30 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 29/04/2019 05:08:32 | Milkyway@Home | Scheduler request completed: got 0 new tasks 29/04/2019 05:19:12 | Milkyway@Home | Sending scheduler request: To fetch work. 29/04/2019 05:19:12 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 29/04/2019 05:19:14 | Milkyway@Home | Scheduler request completed: got 64 new tasks 05:07:31 and 05:08:16 - last 2 task from cache completed. 05:08:30 - last 2 completed tasks reported + request to get new work failed (as few dozen previous too) 05:19:12 - back off times has expired (as there were no completed work to cancel it earlier client wait full back-off)and first request got a lot of work. Same in the next cycle - then all work client got finished again: 29/04/2019 08:34:03 | Milkyway@Home | Scheduler request completed: got 0 new tasks 29/04/2019 08:35:33 | Milkyway@Home | Computation for task de_modfit_81_bundle4_4s_south4s_0_1555431910_4552914_0 finished 29/04/2019 08:35:39 | Milkyway@Home | Sending scheduler request: To fetch work. 29/04/2019 08:35:39 | Milkyway@Home | Reporting 1 completed tasks 29/04/2019 08:35:39 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 29/04/2019 08:35:41 | Milkyway@Home | Scheduler request completed: got 0 new tasks 29/04/2019 08:48:33 | Milkyway@Home | Sending scheduler request: To fetch work. 29/04/2019 08:48:33 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 29/04/2019 08:48:36 | Milkyway@Home | Scheduler request completed: got 57 new tasks 08:35:33 - last task from cache finished 08:35:39 - last task reported to server, request to get new work failed (as all previous while there was some work in cache) 08:48:33 - firs request with empty cache and without reporting completed succeed. And so on - see same behavior in all cycles i checked. Cache empty ==> last tasks reported ==> back-off timer expired ==> successful request ID: 91344 · |
|
Send message Joined: 29 Apr 19 Posts: 19
|
Also, two other things are not included in their (BOINC standard) template SSP: Well looks like what you even do not try to look (just barely skim on top and jumps to conclusions). Not in logs provided not at status pages. There IS info about how much work RTS per app basis - it just in the block below. Tasks by application Application Unsent In progress Runtime of last 100 tasks in hours: average, min, max Users in last 24 hours Milkyway@home N-Body Simulation 1002 129827 2.34 (0.01 - 109.98) 2954 Milkyway@home Separation [b]10104[/b] 441163 0.2 (0.01 - 52.65) 5743 Most of the work RTS is from Separation app and it was this way for long (few month at least). Then i was saying there are about 10 000 tasks ready to sent all the time - i refereed to the Separation app only not total RTS count. Total is about 10k+1k=11k where ~10k are separation tasks and ~1k NBody tasks. And again - where you get this nonsense about 40 seconds is a maximum runtime and millions of tasks per hour? Stats show runtimes in HOURS units, not seconds. 0.2 hours (~700 seconds) is an average value for separation runtimes. While max is a few dozen hours ("stuck" tasks and some old mobile devices based on weak ARM CPUs trying to compete with modern powerful GPUs) And current total throughput of the MW project not a millions of tasks per hour but only 20k-30k tasks per hour (based on RAC and GFLOPS count - about 170 millions cobblestones per day, 220-250 per 1 tasks, ~700k tasks per day, 29k per hour ) . So 10к RTS witch server tries to mains is enough to feed all clients for 20-30 min even if no new tasks being generated at all. But work generator is running online and replenish this supply every few minutes if it goes <10к. ID: 91345 · |
|
Send message Joined: 29 Apr 19 Posts: 19
|
I have got some spare time to test. And now can confirm that problem with getting work from MW happens only with combined requests (report completed tasks + request new). And fast machines and/or short WUs affected through this: if machine fasts enough or WU short enough almost every request will include report of completed WUs, and fail due to it. I did not find any BOINC options to suspend reporting of completed task, so i did it manually. I suspend all tasks close to 100%, forcing BOINC to start new ones. This way i managed to get about half an hour of work without a single task completed (and thus no reported tasks in requests too). And during this time - ALL requests to get new work was successful: 02/05/2019 23:33:33 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:33:33 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:33:35 | Milkyway@Home | Scheduler request completed: got 58 new tasks 02/05/2019 23:35:11 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:35:11 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:35:13 | Milkyway@Home | Scheduler request completed: got 58 new tasks 02/05/2019 23:36:49 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:36:49 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:36:51 | Milkyway@Home | Scheduler request completed: got 58 new tasks 02/05/2019 23:38:26 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:38:26 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:38:28 | Milkyway@Home | Scheduler request completed: got 58 new tasks 02/05/2019 23:40:04 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:40:04 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:40:06 | Milkyway@Home | Scheduler request completed: got 58 new tasks 02/05/2019 23:41:42 | Milkyway@Home | Sending scheduler request: To fetch work. 02/05/2019 23:41:42 | Milkyway@Home | Requesting new tasks for AMD/ATI GPU 02/05/2019 23:41:44 | Milkyway@Home | Scheduler request completed: got 14 new tasks Full log available here: https://pastebin.com/xgEU63uv Note 1: Last request bring only 14 tasks (and few after it - zero) because at this point i hit the server limit of max tasks in progress (600 per host for MW). It is normal and expected. Note 2: only reporting of completed tasks or task aborted during computation lead to a failure with getting new tasks. Reporting of tasks which was aborted before start does not influence getting new work. There is such example: at lines 82-87 of log i aborted task which did not start yet and at lines 88-94 i aborted task which was already running. So my current best guess - there may be something in tasks results that trigger this bug. Like Stderr output or other data from completed tasks included in combined requests. ID: 91355 · |
|
Joseph Stateson Send message Joined: 27 Jun 08 Posts: 641
|
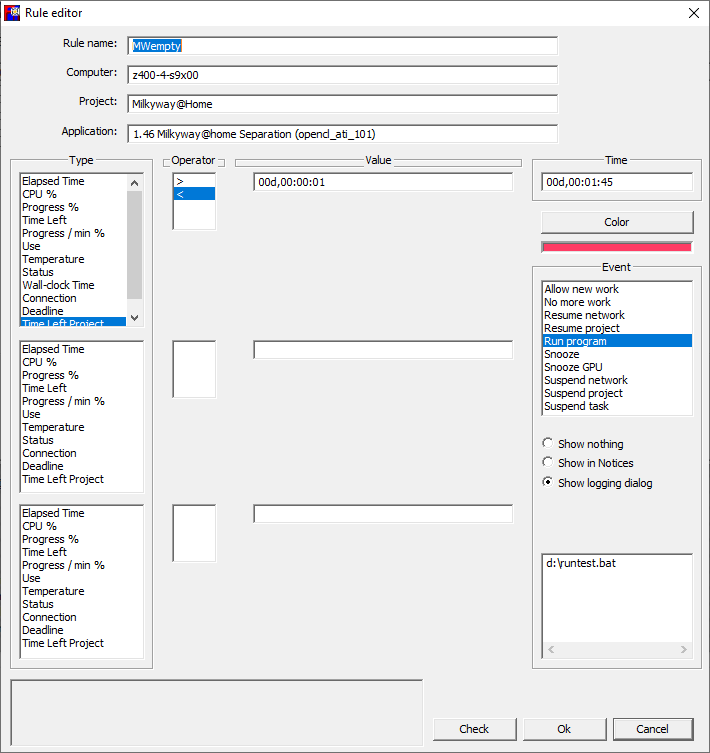
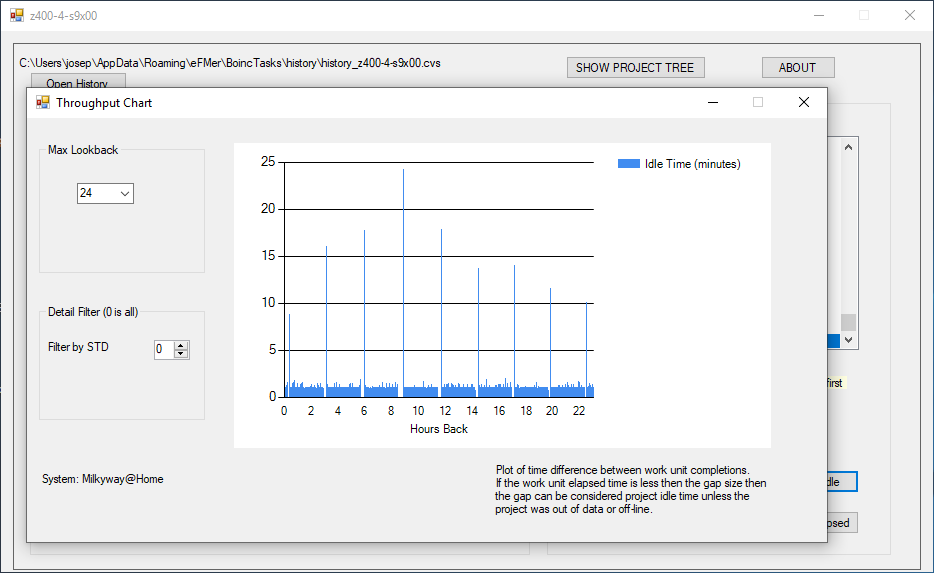
I have got some spare time to test. And now can confirm that problem with getting work from MW happens only with combined requests (report completed tasks + request new). I tried a few things after reading your post. I discovered that if I suspend a single task that the client no longer asks for data after an upload. However, that dead ended as the task had to be un-suspended and I was down to having to do an update after that one task reported. However, I did find an expedient method to get Milkyway work units but it requires BoincTasks. BoincTasks can determine when a project has zero time left. If I wait minimum of 91 seconds after the empty project signal and issue an update request then the project should provide more work. I ran a test of the basic premise and it seems to be work. Unfortunately, the BoincTask program has to go on the computer that is running milkyway as an update cannot be issued to a remote system although I am putting a tool together to do that. The following works: On the system running BoincTasks I created the batch file "d:\runtest.bat" and that file contained the following commands D:\ProgramFiles\boinc\boinccmd.exe --project "http://milkyway.cs.rpi.edu/milkyway/" update time /T >> d:\results.txt In BoincTasks I created the following rule On project TimeLeft < 1 then wait 1 minute 45 seconds before running d:\runtest.bat This worked fine and I found the following in the rule log 03 May 2019 - 00:20:54 Rule(s) ---- Active: 1 03 May 2019 - 00:20:54 Rule: MWempty ---- z400-4-s9x00, Milkyway@Home, 1.46 Milkyway@home Separation (opencl_ati_101), | Time Left Project < 00d,00:00:01 03 May 2019 - 00:20:54 ============================================================================== ---- 03 May 2019 - 02:00:41 Rule: MWempty, trigger ---- z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00), 03 May 2019 - 02:00:41 Rule: MWempty ---- Program executed ok: d:\runtest.bat () 03 May 2019 - 02:14:42 Rule: MWempty ---- No longer active: z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00) 03 May 2019 - 04:48:29 Rule: MWempty, trigger ---- z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00), 03 May 2019 - 04:48:29 Rule: MWempty ---- Program executed ok: d:\runtest.bat () 03 May 2019 - 05:02:29 Rule: MWempty ---- No longer active: z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00) 03 May 2019 - 07:35:21 Rule: MWempty, trigger ---- z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00), 03 May 2019 - 07:35:21 Rule: MWempty ---- Program executed ok: d:\runtest.bat () 03 May 2019 - 07:39:22 Rule: MWempty ---- No longer active: z400-4-s9x00, Milkyway@Home, (Time left project <00d,00:00:00) The event log for my system showed the request to do the update. 190 Milkyway@Home 5/3/2019 2:00:41 AM update requested by user 191 Milkyway@Home 5/3/2019 2:00:45 AM Sending scheduler request: Requested by user. --- 205 Milkyway@Home 5/3/2019 4:48:29 AM update requested by user 206 Milkyway@Home 5/3/2019 4:48:33 AM Sending scheduler request: Requested by user. --- 311 Milkyway@Home 5/3/2019 7:35:21 AM update requested by user 312 Milkyway@Home 5/3/2019 7:35:23 AM Sending scheduler request: Requested by user. However, the update occurred on my PC that has BoincTasks not on the system that had run out of data, but at least this shows the concept works. Looking at the 7:35 time (logs do not back far enough for the other two) on the offending system I see the following 78694 Milkyway@Home 5/3/2019 7:32:33 AM Reporting 13 completed tasks 78695 Milkyway@Home 5/3/2019 7:32:33 AM Requesting new tasks for AMD/ATI GPU 78696 Milkyway@Home 5/3/2019 7:32:35 AM Scheduler request completed: got 0 new tasks 78697 Milkyway@Home 5/3/2019 7:38:11 AM Sending scheduler request: To fetch work. 78698 Milkyway@Home 5/3/2019 7:38:11 AM Requesting new tasks for AMD/ATI GPU 78699 Milkyway@Home 5/3/2019 7:38:16 AM Scheduler request completed: got 602 new tasks … 78720 Milkyway@Home 5/3/2019 7:39:51 AM Sending scheduler request: To fetch work. 78721 Milkyway@Home 5/3/2019 7:39:51 AM Requesting new tasks for AMD/ATI GPU 78722 Milkyway@Home 5/3/2019 7:39:55 AM Scheduler request completed: got 298 new tasks There was only a 5:43 delay from getting "0" to getting "602" tasks. and about a minute later the additional 296 came in. This system has 4 GPUs so I expect 200*4 but the close to 900 is ok I have a program HERE that is capable of issuing an update request across the internet and I will mod it to run from that batch file. However, all that will get me on the "7:33;35" empty signal is to reduce the idle time to about 2 or 3 minutes. This particular idle gap, is only 5:43 and I have seen others much longer. This graph shows the results. The 7:33:35 idle is at the one that goes up to about 9 minutes. That is because completion time on this system is 3 minutes (5 concurrent tasks) so 3 + 5:43 is almost 9 minutes. Note the almost 25 minute delay about 9 hours back. When I implement this scheme the idle times will drop but will still be present. ID: 91362 · |
|
Send message Joined: 29 Apr 19 Posts: 19
|
Limit for tasks in progress is 200 per GPU plus some (40 if i recall correctly) per CPU core. But i don't interested in such workarounds. I already found own some time ago. Just a very simple script which force updates of the project every 2 min via boinccmd. :start timeout 120 boinccmd.exe --project milkyway.cs.rpi.edu/milkyway update goto start Works very well for me: every few updates client has nothing to report (no completed tasks yet) and thus request to get new work succeed. And cache newer run dry while this script is working. But it just workaround, not a fix. I want to find root of the problem and pass it to BOINC devs so they can smash this bug for good. ID: 91378 · |
|
Joseph Stateson Send message Joined: 27 Jun 08 Posts: 641
|
Limit for tasks in progress is 200 per GPU plus some (40 if i recall correctly) per CPU core. I have too many tasks completing all the time. Running that loop would generate 'Last request too recent". It would eventually work right near when the queue was empty which is actually an improvement over my method that waits will all tasks are complete. I don't think this "bug" will get fixed anytime soon. Lot of developers are grad students or volunteers. At one time MW sent tasks to GPUs that did not have double precision hardware and there would be 1000's of errored out tasks as they kept sending more work units. I suspect that some users and staff on other projects might consider this bug to actually be a feature as it allows other projects to get some work. I have systems I need to access remotely so it is convenient to be able to issue the update across the internet which I now have the tools to do. Here is before and after image of improvement. However, I will try putting my program in a loop like yours and see if I can cut the idle time down more. 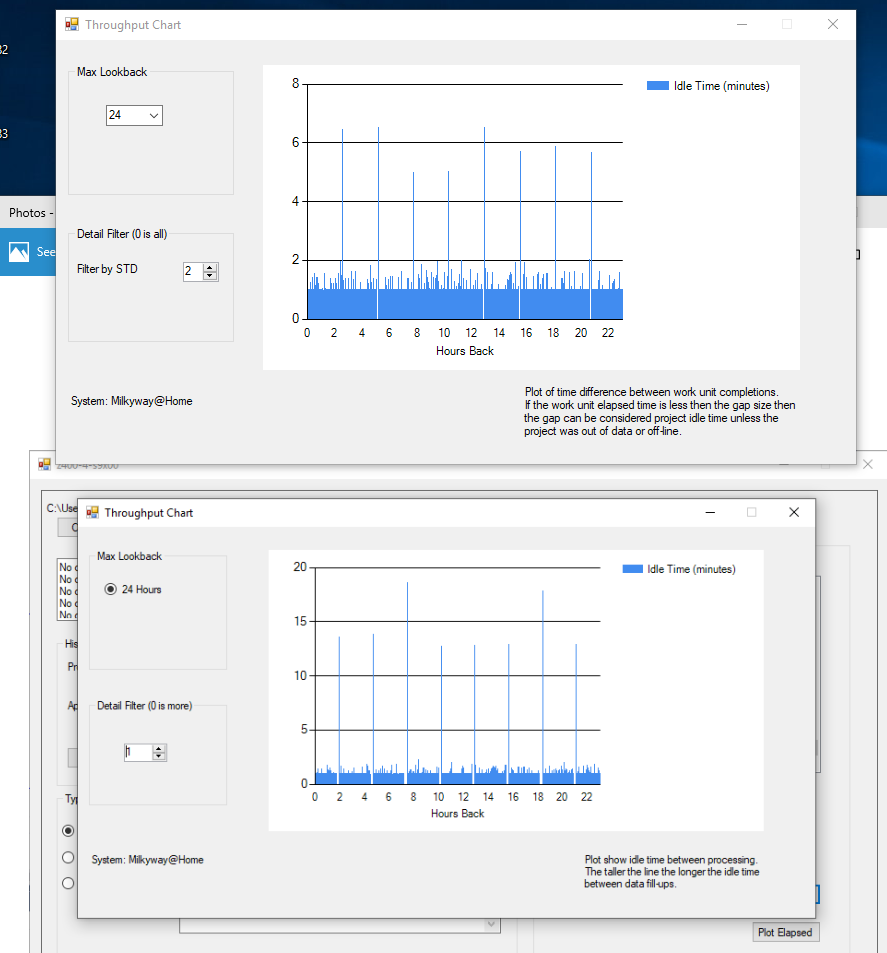 ID: 91388 · |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Copyright © 2024 University of California.
Permission is granted to copy, distribute and/or modify this document
under the terms of the GNU Free Documentation License,
Version 1.2 or any later version published by the Free Software Foundation.